Sur un projet d’automatisation nous avons eu besoin de récupérer le vCenter d’un cluster via les REST API de vROps (aka VMware Aria Operations). Nous avons, dans un premier temps, regardé du côté du swager de vROps (https://YourvROps/suite-api/doc/swagger-ui.html), qui nous avait mis sur plusieurs pistes… mais au final c’est ultra simple.
Nous allons détailler les étapes via Postman :
- Obtention du token dans vROps
- Recherche du cluster dans vROps (à partir de son nom) afin d’obtenir son id vROps.
- Recherche du vCenter associé à l’id du cluster
Obtention du token :
Call type : POST
Url : https://YourvROps/suite-api/api/auth/token/acquire
Body :
{
"authSource" : "Domain",
"password" : "Password",
"username" : "Username"
}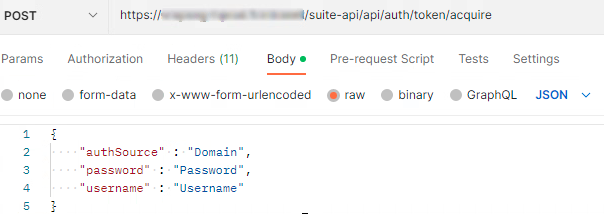

Copier le token (encadrer en rouge) reçu dans le body.
Recherche du cluster :
Call type : GET
Url : https://YourvROps/suite-api/ressources?name=CluserSearch
Headers: ajoutez les keys ci-dessous.
– “Content-Type” value “application/json”
– “Authorization” value “vRealizeOpsToken + le token copié précédemment”
– “Accept” value “application/json”
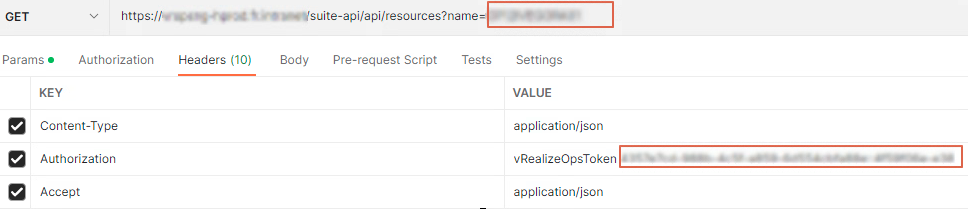
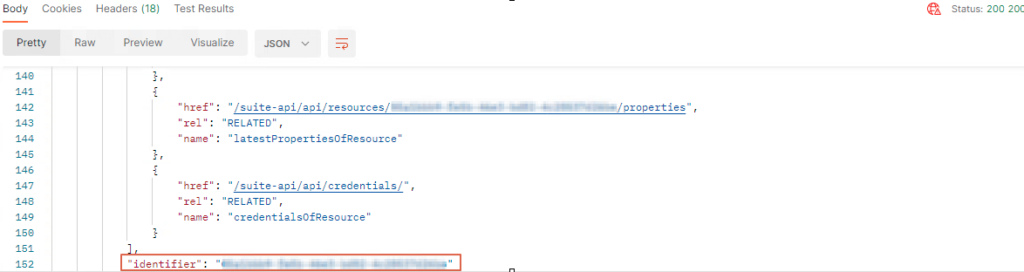
Dans le Body récupérer l’id du cluster dans l’attribut “identifier”
Recherche du vCenter associé à l’id du cluster :
Call type : GET
Url : https://YourvROps/suite-api/ressources/IdCluster/properties
Headers: ajoutez les keys ci-dessous.
– “Content-Type” value “application/json”
– “Authorization” value “vRealizeOpsToken + le token copié précédemment”
– “Accept” value “application/json”
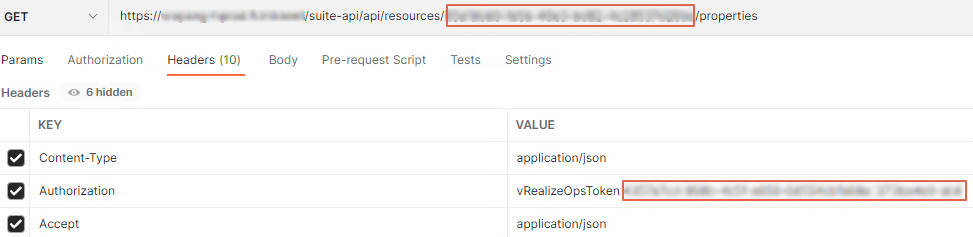
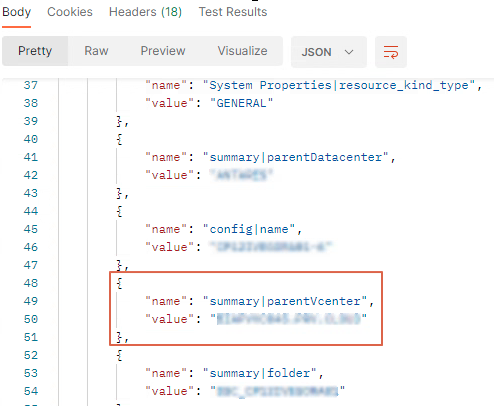
Dans le body, rechercher la value de l’attribut name: summary|parentvCenter et c’est tout bon 😉
![]()

 + )
+ )