
Comme vous le savez Horizon view repose sur une base ADAM repliquée entre les divers Connections Servers, c’est bien… c’est beau tant que ça se réplique bien, le jour où vous rencontrez des problèmes de réplication alors il sera grand temps de vous souvenir de votre expérience AD. De notre côte sur une infra 7.3 avec 3 connections Servers nous avons rencontré les event id 2091 et 2092.
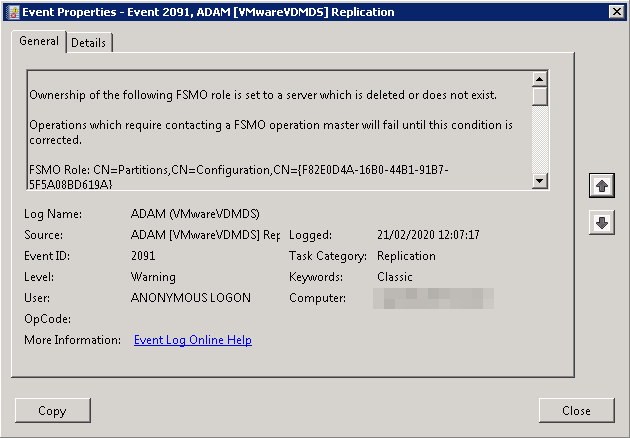
Ownership of the following FSMO role is set to a server which is deleted or does not exist.
Operations which require contacting a FSMO operation master will fail until this condition is corrected.
FSMO Role: CN=Partitions,CN=Configuration,CN={F82E0D4A-16B0-44B1-91B7-5F5A08BD619A}
FSMO Server DN: CN=NTDS Settings\0ADEL:8f620d83-00d8-4b15-87fc-97430126a71e,CN=Server01$VMwareVDMDS\0ADEL:b5ebd2b8-1345-48ab-bb4c-554090afca20,CN=Servers,CN=Default-First-Site-Name,CN=Sites,CN=Configuration,CN={F82E0D4A-16B0-44B1-91B7-5F5A08BD619A}
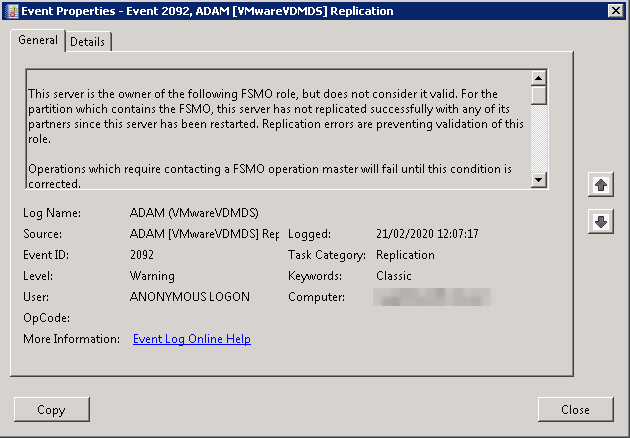
This server is the owner of the following FSMO role, but does not consider it valid. For the partition which contains the FSMO, this server has not replicated successfully with any of its partners since this server has been restarted. Replication errors are preventing validation of this role.
Operations which require contacting a FSMO operation master will fail until this condition is corrected.
FSMO Role: CN=Schema,CN=Configuration,CN={F82E0D4A-16B0-44B1-91B7-5F5A08BD619A}
Nous comprenons rapidement que nous n’avons pas de schema master, pour confirmer cela on ouvre un “Active Directory Schema” (via une mmc)

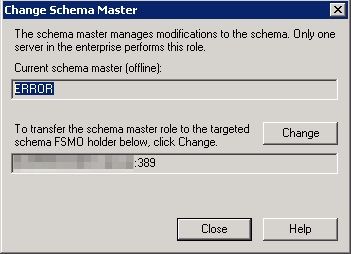
Afin de pouvoir forcer un schema master, nos amis de VMware nous ont pondu la KB2083758 qui va nous permettre de configurer un nouveau Shema Master (attention l’étape 8 n’est pas obligratoire, nous l’avons rajoutée car dans notre cas il fallait forcer le “naming master”).
- To open the command prompt:
- Click Start.
- Right-click Command Prompt and then click Run as administrator.
- In the command prompt, run this command:
dsmgmt - In the
dsmgmtcommand prompt, run this command:
roles - In the
fsmo maintenancecommand prompt, run this command:
connections - In the
server connectionscommand prompt, run this command:connect to servercomputername:portnumber
where computername:portnumber is the computer name and communications port number of the AD LDS instance that you want to use as the new schema master. - In the
server connectionscommand prompt, run this command:quit In thefsmo maintenancecommand prompt, run this command:seize schema master- (Etape rajoutée) In the
fsmo maintenancecommand prompt, run this command:seize naming master - Type exit and press Enter
Une fois les commandes passées nous avons bien un nouveau schema master et plus d’erreurs dans les events log de nos Connection Server
Server “Server01:389” knows about 2 roles
Schema – CN=NTDS Settings,CN=Server01$VMwareVDMDS,CN=Servers,CN=Default-First-Site-Name,CN=Sites,CN=Configuration,CN={F82E0D4A-16B0-44B1-91B7-5F5A08BD619A}Naming Master – CN=NTDS Settings\0ADEL:8f620d83-00d8-4b15-87fc-97430126a71e,CN=Server01$VMwareVDMDS\0ADEL:b5ebd2b8-1345-48ab-bb4c-554090afca20,CN=Servers,CN=Default-First-Site-Name,CN=Sites,CN=Configuration,CN={F82E0D4A-16B0-44B1-91B7-5F5A08BD619A}
![]()














{kind=link}