
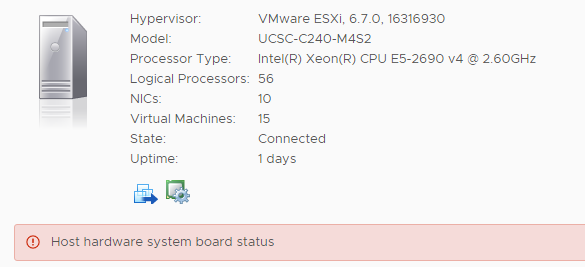
Sur plusieurs Vcenter 6.5/6.7 nous avons rencontré l’erreur “Host hardware system board status” sur des ESXi 6.5/6.7 (UCS-240-M4). En regardant côté CIMC (Cisco Integrated Management Controller) on n’a rien constaté au premier abord (pas d’alerte hardware ou autre). En navigant dans la CIMC dans l’onglet SEL (System Event Log) nous avons constaté que ce dernier était full, en faisant un clear log cela nous a permis de corriger l’alarme “Host hardware system board status”.
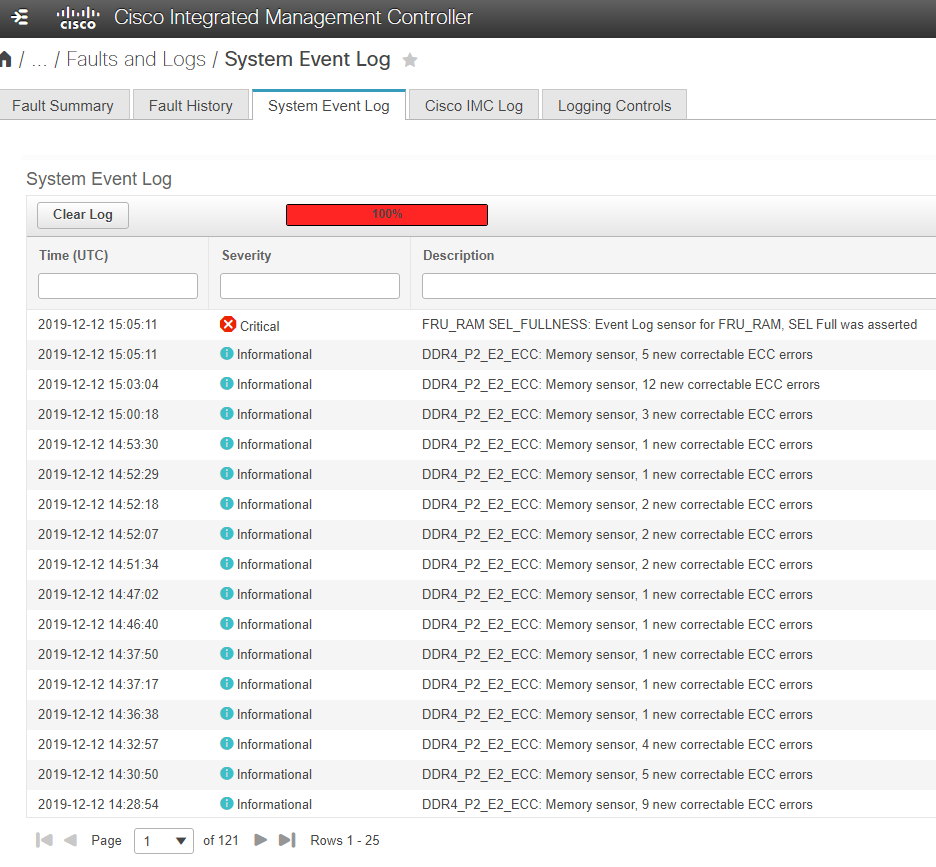
Il est aussi possible de faire un clear du SEL via SSH et REST API
En SSH :
Se connecter en SSH sur le serveur puis entrer les commandes ci-dessous :
- show sel (si vous souhaitez au préalable visualiser le pourcentage d’occupation des log)

- scope sel

- clear (le screeenshoot ci-dessous montre le résultat de la commande show après un clear



En Rest API :
- https://10.10.10.10/redfish/v1/Chassis/1/LogServices/SEL/Actions/LogService.ClearLog
Si vous souhaitez plus d’infos sur les CLI CISCO UCS c’est juste en dessous.
![]()




{kind=link}